
The Hidden Tax Your LLM Pays for Bad Tokenization
This is Part 2 of a three-part series on tokenization and multilingual AI. Part 1 introduced the problem. Part 3 covers the compounding tax stack and the path forward.
What the Tokenizer Breaks, the Model Must Fix
You might have used Gemma, Qwen or ChatGPT and they do speak other languages, so you might want to challenge the claims I laid down.
The truth is there's an alternative path to language-specific tokenizers. Gemma pioneered a massive 250k token vocabulary size and Qwen followed suit in its latest 3.5 edition. Since so many languages shared the same writing script, it means latin, arabic and cyrillic alphabets are used to write completely different things and the tokenizer reflects this by producing "universal" tokens. Tokens that can be used to compress text from any language, but whose boundaries do not have a particular meaning for a given language.
But even if tokenization boundaries are not meaningful, the model under the pressure of gradient descent still has to find a way to mimic the training data and generate plausible responses. And it's the middle layers who bear this cost. But those middle layers are not surplus capacity sitting idle. They're simultaneously responsible for syntactic composition, semantic integration, reasoning and you know, doing the task you prompted the LLM for. The tokenizer sets the morphological reconstruction bill. The middle layers pay it out of a shared budget.
The cost you're paying for is a much dumber model. I know because developers come to Sawalni with this exact problem: "My agent works great in french or english. But if a user asks in Darija, it crashes in quality and becomes unusable." This is the cost frontier LLMs with the appearance of multilingualism must pay: less intelligence because half of its brain is too busy making sense of the non-sense pieces of text.
"But it works well in my language!" - for all things equal (model size, training data, compute) it would have worked better. The LLM is carrying deadweight holding it back on every token it generates.
Another piece of evidence comes from the "Tokenization Falling Short" (EMNLP 2024) paper who shows that scale partially recovers the gap introduced by bad tokenization. If scale buys back performance, then smaller models are using raw parameter budget as a substitute for clean input. That means you're not getting a 7B model's worth of reasoning, you're getting a 7B model spending a meaningful fraction of its capacity on reconstructing what should have been in the tokens to begin with.
Competing Directions: When Tokens Mean Too Many Things at Once
There are more than 500 languages from 20+ linguistic families using the latin alphabet for writing, under very different assumptions and with overlapping but ultimately very different semantics, phonetics, everything-ics. So when a model trains on multilingual data with a bad tokenizer (is there even a good one), each token needs to capture in its token embeddings a certain meaning reflecting all the contexts in which it was encountered.
A token that appears in too many morphologically distinct contexts doesn't converge to a clean embedding, it accumulates competing gradient updates, one for each context it appears in across training. It needs to serve too many directions simultaneously.
Anthropic's superposition research makes the mechanism precise: when a model must represent more features than it has embedding dimensions, it encodes multiple features per direction, with interference as the price of admission. This is exactly what happens when BPE segments morphologically rich words by frequency rather than meaning. The same token fragment recurs across unrelated contexts, accumulating competing gradient updates from each one. The embedding can't converge to a clean representation because it's being asked to serve too many directions at once.
The middle layers are then where this interference resolves. The polysemanticity emergence literature shows that competing feature directions converge specifically in middle-layer processing, meaning yet more of the shared capacity budget is consumed not on reasoning but on disambiguation the tokenizer manufactured in the first place. The "BPE Gets Picky" paper (EMNLP 2024) names this directly: standard BPE creates under-trained tokens by over-allocating vocabulary to high-frequency but semantically hollow units, degrading embedding parameter utilization overall.
To be precise about what's established vs. open: no single study has drawn a clean empirical line from boundary misalignment → elevated embedding directional variance → measurable reasoning degradation at fixed parameter count. That line is implied by the convergence of these findings. Closing it empirically is one of the specific questions this work is pursuing.
Typos, Diacritics, and the Brittleness Cascade
The fastest way to see what's wrong with discrete tokenization is to slightly corrupt the input. Interestingly, this problem is not unique to low-resource languages and impacts everyone.
Let's crank up some code and look closer:
variants = [
"tell me", # base
"Tell me", # capitalization
"tell me", # double space
"tllm e", # transposition typo
"tellme", # omission typo
"teell me", # repetition typo
"tell mé", # diacritic
]
base_ids = set(tok.encode(variants[0]))
for v in variants:
ids = set(tok.encode(v))
jaccard = len(base_ids & ids) / len(base_ids | ids)
print(f"{v!r:20} Jaccard: {jaccard:.2f} {tok.tokenize(v)}")
# Result:
#
# 'tell me' Jaccard: 1.00 ['tell', 'Ġme']
# 'Tell me' Jaccard: 0.33 ['Tell', 'Ġme']
# 'tell me' Jaccard: 0.67 ['tell', 'Ġ', 'Ġme']
# 'tllm e' Jaccard: 0.00 ['t', 'll', 'm', 'Ġe']
# 'tellme' Jaccard: 0.33 ['tell', 'me']
# 'teell me' Jaccard: 0.25 ['te', 'ell', 'Ġme']
# 'tell mé' Jaccard: 0.33 ['tell', 'Ġmé']
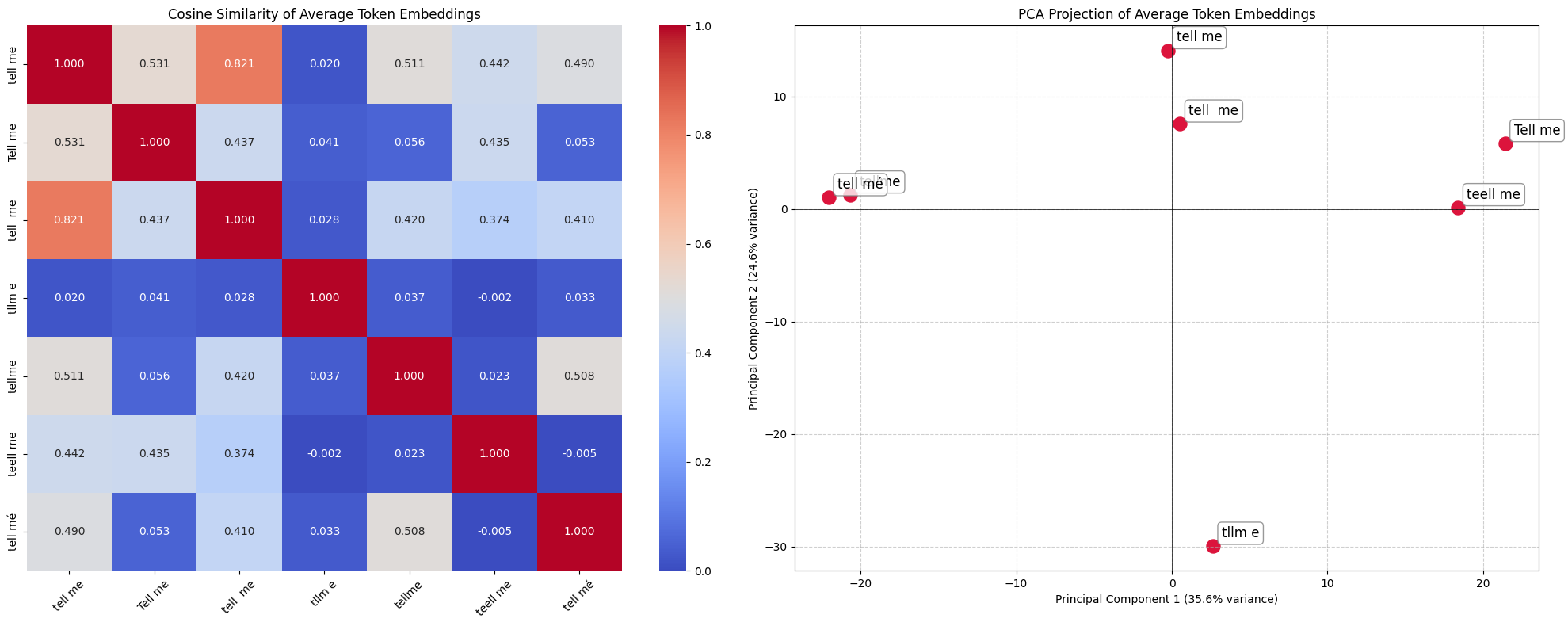
The Jaccard column tells part of the story. "tell mé" shares essentially nothing with "tell me". No overlap in tokens, no structural relationship, no shared gradient history. A human reads both as identical intent in under 100 milliseconds. As far as model is concerned, those are two completely foreign sequences.
If the model learns to recover some of these typos, it's not at the token embedding level. These are token embeddings and they should not be so further apart. In an ideal world, similarity would be close to 1:
The issue is predictably not much better in other languages, here in Moroccan Arabic:
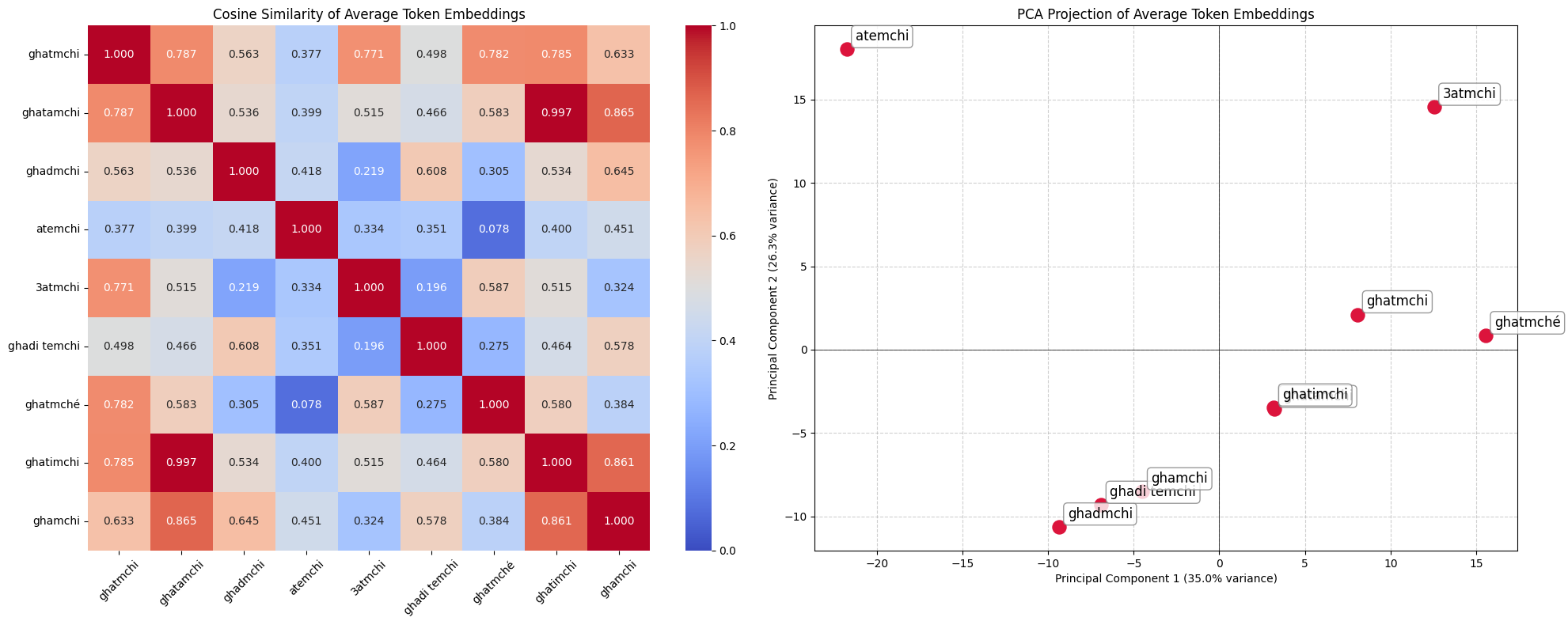
These are inconveniences for high-resource languages, which have seen enough variant co-occurrences to embed them nearby in representation space. For low-resource languages, those correspondences were never learned because the data to build them never existed. Khasi's ï and ñ are stripped or replaced at rates of 18–50% in model outputs and those characters are not decorative, they are meaning-bearing. A leading space creates a completely different token identity: ▁tell != tell. In agglutinative languages, this interacts destructively with prefix and suffix morphology at every word boundary.
Let's recap: when the model encounters a corrupted or variant-form input for a low-resource language, it has to do three things in its middle layers serially: reconstruct the intended characters from sub-token fragments, recover the morphological structure from those fragments, and map back to the semantic concept. In a well trained model with a good tokenizer, this is the role of the embedding layer, leaving the later middle layers to do useful work.
For a high-resource language with a well-fitted tokenizer, this chain barely activates since token embeddings are immediately usable. For a low-resource language with a misaligned tokenizer, it fires on nearly every token.
Next: Part 3 — Beyond Tokenization: The Four Taxes and the Path Forward, where we look at how these problems compound and what might actually solve them.
Related posts
Interested in collaboration?
I'm open to research partnerships, compute collaborations, or contributing to low-resource language AI.
Get in touch