
Why I stopped trusting the official Wikipedia dataset, and what I did about it
It all started last June 2025 with a DM from a friend, member and contributor to the Moroccan Wikipedia community.
"Are you using the current version of Moroccan Arabic Wikipedia? The official dataset release is severely outdated. We added so many cool articles nowhere to be found on huggingface"
He was right. I was running a 2023 snapshot in 2025. The official Wikipedia dataset on HuggingFace - the one hundreds of NLP researchers and big labs use without questioning, was frozen in time. I checked the article count: 8,000 in the dataset. 11,000+ in the website. A full 30% of the language's knowledge no one was making use of, locked out of every model trained on that data. There are people requesting an update on huggingface, but no visible progress.
I had two choices. Shrug and move on, fully knowing I'm missing out on pristine data. Or find out how deep the rabbit hole went.
And so I shrugged and moved on. Nah, of course not. واش حنا عسكر ولازمر؟ (untranslatable)
Downloading the raw Wikipedia dump for Moroccan Arabic was easy enough - Wikimedia publishes monthly dumps in their official portal, only one curl away. But what waited inside was another thing entirely.
Wikipedia articles are written in MediaWiki, a markup language that looks like it should be simple, but isn't. It's accidentally Turing-complete. Templates call other templates. Conditionals branch based on language-specific rules. Categories are written in the local script, [[تصنيف:foo]] in Arabic, not [[Category:foo]]. A naïve cleaner is very likely to produce broken text (and I had people politely complaining about it, early on in the project)
To get from a raw dump to clean, plain-text prose, you basically have three paths:
- Render it with a real MediaWiki engine. You get HTML, which you then parse back into text. Faithful but slow, complex, and expensive to run at scale.
- Parse it into a structured tree using
mwparserfromhell. Much easier, but templates, conditionals, and language-specific tags still require running actual MediaWiki logic that the library simply doesn't handle. Remember, MediaWiki is almost a programming language. - The pragmatic compromise: use
mwparserfromhellfor structure, then write deterministic rules to handle the last mile manually, making use of smart defaults and some informed assumptions.
I went with option 3, and got a text corpus free of templates. But it wasn't over: I still needed to handle the localized labels.
Every Wikipedia edition names its namespaces differently. Category in English is تصنيف in Arabic, Catégorie in French, Tispir in Talish and ⴰⵙⵎⵉⵍ in Tifinagh Tamazight. If your cleaner doesn't know what to strip, those labels end up in your training data as legitimate text.
So I collected them. All of them. For every Wikipedia edition I could find. It wasn't too complicated to automate, but I had to add cleanup rules after manual inspection because data is always noisy. The result became its own artifact: omarkamali/wikipedia-labels, a per-language dataset of every MediaWiki namespace label, released publicly on HuggingFace.
By the time I had Moroccan Arabic working cleanly, I realized something.
The pipeline was general. I could run it on every Wikipedia edition, nothing unique to Moroccan, and many others could benefit from it.
So I did.
One Language Was a Proof of Concept. 340 Was a Different Animal.
I thought at first, I have a decent machine, and a solid pipeline. Let me parameterize the Wikipedia edition, then loop over every language on wikipedia.
The first wall I hit was the Wikipedia API itself.
I had written a respectful downloader. Rate-limited, well-behaved. Wikipedia still bans me on the regular for what seems like inscrutable reasons. More often than not, I am hit with a bare 404 error as if that language never existed, but the next language works. I'd come back after an hour, sometimes two, restart the failed downloads, and watch some work while others fail again three languages later. Retries are useless. You have to stay in the doghouse for the current run.
Range requests helped on the other hand. If a download died halfway through an 8GB dump, I could resume from the byte offset instead of starting over. I learned this the hard way after restarting the larger languages over and over for days. But it was a band-aid on a process that was fundamentally fragile when run at scale.
The second wall was storage.
Is raw data from Wikipedia very large? No, it's reasonably sized, if you only download the text dump. The largest compressed dump clocks in at around 24GB for the English Wikipedia edition, with others following a power law.
It does get trickier when you realize you have to keep many copies of that data for the sake of the pipeline: 1) store the download on disk then 2) extract it into raw MediaWiki and 3) store the cleaned corpus. It's even more challenging when you try to parallelize the process.
My laptop has "only" 1TB of disk space. It's not much when you do data engineering (looking at you, HF cache!). It's much worse when Xcode, Android Studio, and Davinci Resolve (and some services on Docker) are added to the mix.
I once made the hopeful mistake to leave the pipeline running overnight for those 24/7 maximum productivity points. I woke up to a frozen mac. It was so bad, running rm on literally anything hit me with No space left on device. Not good. My laptop has some critical services running on it, and it’s part of the compute serving and training Sawalni, the LLM I trained.
Pro-tip: If this is ever you, or myself again in the future, you can delete an old time machine snapshot as a last resort with tmutil deletelocalsnapshots. This gave me just enough space to start for rm to work and start recovering the situation.
The third wall was memory.
That large data on disk has to be loaded onto memory at some point. My laptop has 128 GB of RAM. Running even 8 languages in parallel pushed it to 60% memory utilization on this process alone. I could run 1-2 languages simultaneously at best. At that rate, processing all 340 editions would take days if not weeks.
That was unacceptable. I had to optimize it more.
While some stages can be streamed, others cannot, and with multiprocessing it means different languages can be at different stages simultaneously and start causing some severe memory bottlenecks. The memory issue often turned into a storage issue thanks to the wonders of swap, causing my maxed out Mac to freeze with yellow splats of color on the screen, briefly restarting afterwards.
The key was to understand the specific bottleneck. I could have gone with flamegraphs but where's the fun in that? I reduced the number of workers, cranked up htop and started correlating the good old way, split my terminal in two with the left terminal showing processes and the right one tracing the logs and steps of the pipeline. I did eventually isolate it down to complex nested mediawiki templates. The issue was critical bits competing when multiple workers are running in parallel, sometimes conspiring to blow up my system's memory.
I first went with a mutex lock gating the most taxing processing steps. While it worked, this slowed everything down to a crawl, taking almost a week. I ended up implementing a memory monitor which prevents scheduling new tasks until memory goes below a critical threshold. Same idea as the mutex but more dynamic, allowing me to squeeze more from my hardware.
Before: 12-14 days if I don't encounter too many failures
After: 3 days on my laptop, <24 hours on a server
Those were 14 days where my laptop was chugging along with great difficulty, where my friends would complain that my voice is breaking on Discord, under the constant fear and pressure of 98% of the disk being full.
If I were starting over, I would first travel back in time and buy a mac with more storage. That, or I'd aim for securing cloud resources before attempting it in the first place. An appropriate server would cost a lot more than I'm willing to pay though - it's only volunteering.
The one thing I still haven't solved: optimizing uploads and making them reliable. Between the amount of files to upload, the strict rate limits from Huggingface, how to best batch uploads while minimizing storage ... I occasionally end up with failed splits. Given storage needs to be cleared aggressively, a failed upload throws the pipeline off-track. If you've dealt with big dataset uploads before, I'd genuinely like to learn from your experience.
The Result That Made It All Worth It
Today, omarkamali/wikipedia-monthly is updated every month, and covers 340+ Wikipedia editions. I also include subsets of 10k, 5k and 1k articles so you don't hit the same memory and storage issues I encountered.
And it was all worth it. I received so much positive feedback for this work privately and in public. Nous Research trained Hermes 4 using it. There are papers citing it from the HAL lab at INRIA, and another in Deep Learning. People are training models on it.
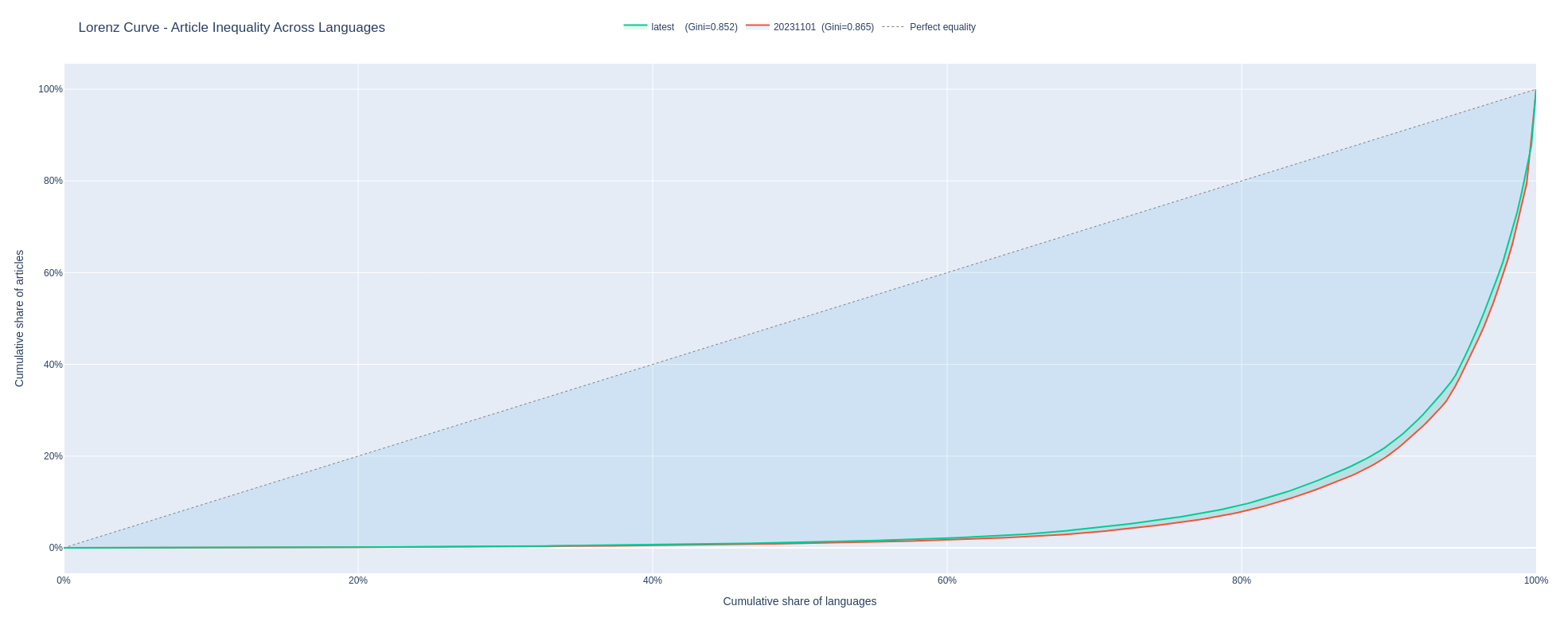
 The latest version is built on a 2026 snapshot, three years ahead of the official HuggingFace Wikipedia dataset that most researchers still use by default.
The latest version is built on a 2026 snapshot, three years ahead of the official HuggingFace Wikipedia dataset that most researchers still use by default.
Some fun stats
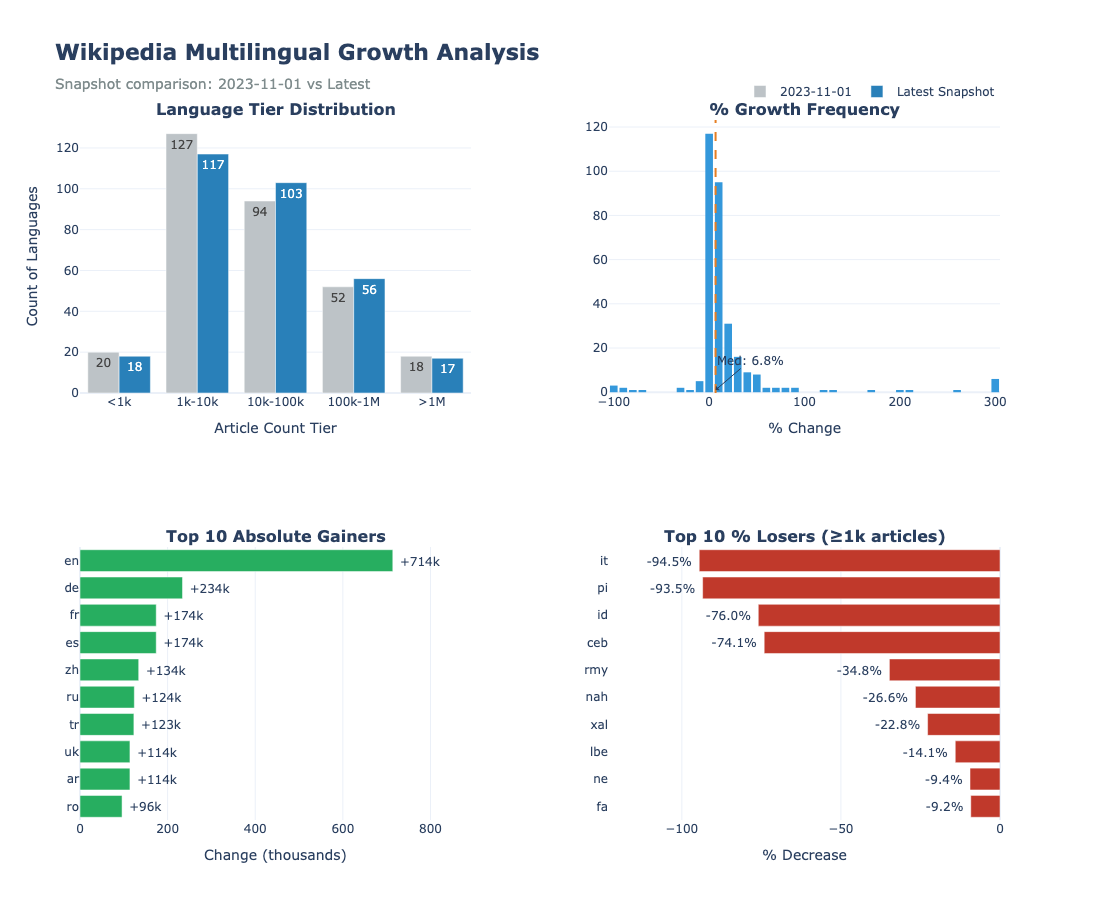
For Moroccan Arabic, that's the difference between 8,000 articles and 11,000+. For English it's a whopping 700,000 articles missing between the two editions. Arabic? 100,000. Other Wikipedias underwent significant cleaning improving their quality. Overall, the amount of data increased by a median of 6.8%, with some languages experiencing explosive growth.
| Lang | 2023 Wikipedia | omarkamali/wikipedia-monthly | % Growth | Language |
|---|---|---|---|---|
| ff | 2,420 | 24,200 | +900% | Fula |
| glk | 7,050 | 48,600 | +589% | Gilaki |
| shi | 1,780 | 10,900 | +512% | Tachelhit |
| skr | 5,820 | 24,300 | +318% | Saraiki |
| mzn | 18,700 | 66,600 | +256% | Mazanderani |
Also worth mentioning: 31 languages were added to Wikipedia after 2023, therefore never having any text corpus until I released this one.
 Stay tuned for the next post where I expand on the technical bits behind Wikilangs, a downstream project enabled by Wikipedia Monthly.
Stay tuned for the next post where I expand on the technical bits behind Wikilangs, a downstream project enabled by Wikipedia Monthly.
Links:
- omarkamali/wikipedia-monthly, the dataset on Hugging Face.
- Wikisets, a library to easily prepare LLM pretraining datasets from Wikipedia Monthly.
- Wikilangs, an atlas of languages, with 1500+ NLP models and resources for every featured language.
- Wikilangs Games, a Wordle-like guessing game, made for non-English speakers who want to connect with their language.
- omarkamali/wikipedia-labels, the namespace labels from wikipedia.
Related posts
Interested in collaboration?
I'm open to research partnerships, compute collaborations, or contributing to low-resource language AI.
Get in touch