
Tokenization is Killing Our Multilingual LLM Dream
You're training an LLM for your language and you did everything right. You spent weeks, maybe months, carefully curating the data. You cleaned it, deduplicated it, filtered aggressively. You picked a reasonable architecture, tuned the learning rate, watched the loss curve behave exactly as expected. The norm looks good. The eval perplexity is respectable. You run some inference and the model is, frankly, crap. It hallucinates structure. It loses track of morphology mid-sentence. It fails on inputs that are trivially easy for a native speaker. You check the data again. You check the architecture again. The problem is somewhere you haven't looked yet.
It's the front door. It was always the front door.
In 2023, I trained the first version of Sawalni.ma - a language model for Moroccan Arabic and Amazigh. I spent nights curating data while model iterations trained, and none of them met the quality of my data. But English models worked great. This experience set me on a years-long investigation, and building Wikilangs shortly after - 1800+ NLP models across 340+ Wikipedia languages, I watched the same pattern repeat without exception. Every language that struggled, struggled first at the token boundary.
Put simply, when you have a good representation, you don't need as much data. Tokenization is the tax that low-resource languages cannot afford to pay, and they're being charged it on every token, in every layer, for every variant their speakers write.
This is Part 1 of a three-part series. Part 2 covers how bad tokenization wastes model capacity. Part 3 looks at the compounding tax stack and the path forward.
Unpacking Tokenization
LLMs are big balls of numbers taking numbers as inputs and to output other numbers. This is easy for images since pixels are also numbers at the end of the day. But how can an LLM manipulate text?
Tokenization is the step that converts raw text into numbers a language model actually works with, its atomic pieces of meaning, its legos. That's how you get tokens, the units you are billed by when using a commercial LLM provider.
When you type in a prompt, the text is cut into strips (tokens) by a pair of scissors (the tokenizer) before the model ever reads it - and you didn't choose where to cut. If the cuts happen to land on meaningful units, whole words, recognizable morphemes, or syllables, the model can reconstruct meaning quickly. If the cuts are arbitrary, it's doing extra work just to figure out what it's looking at before it can begin to understand it. Everything that follows is about what happens when those cuts are systematically bad.
The LLM produces the answer to your prompt by generating one token at a time. In this case, think of tokens as the keys on a keyboard the model is allowed to press. It has a fixed set and a limited budget for how many it can press per response. Here's where it gets interesting, after each token, the LLM can choose what to write next. When a word is cut in a non meaningful way, the LLM is presented with options that do not make sense. Options it shouldn't have been presented with in the first place.
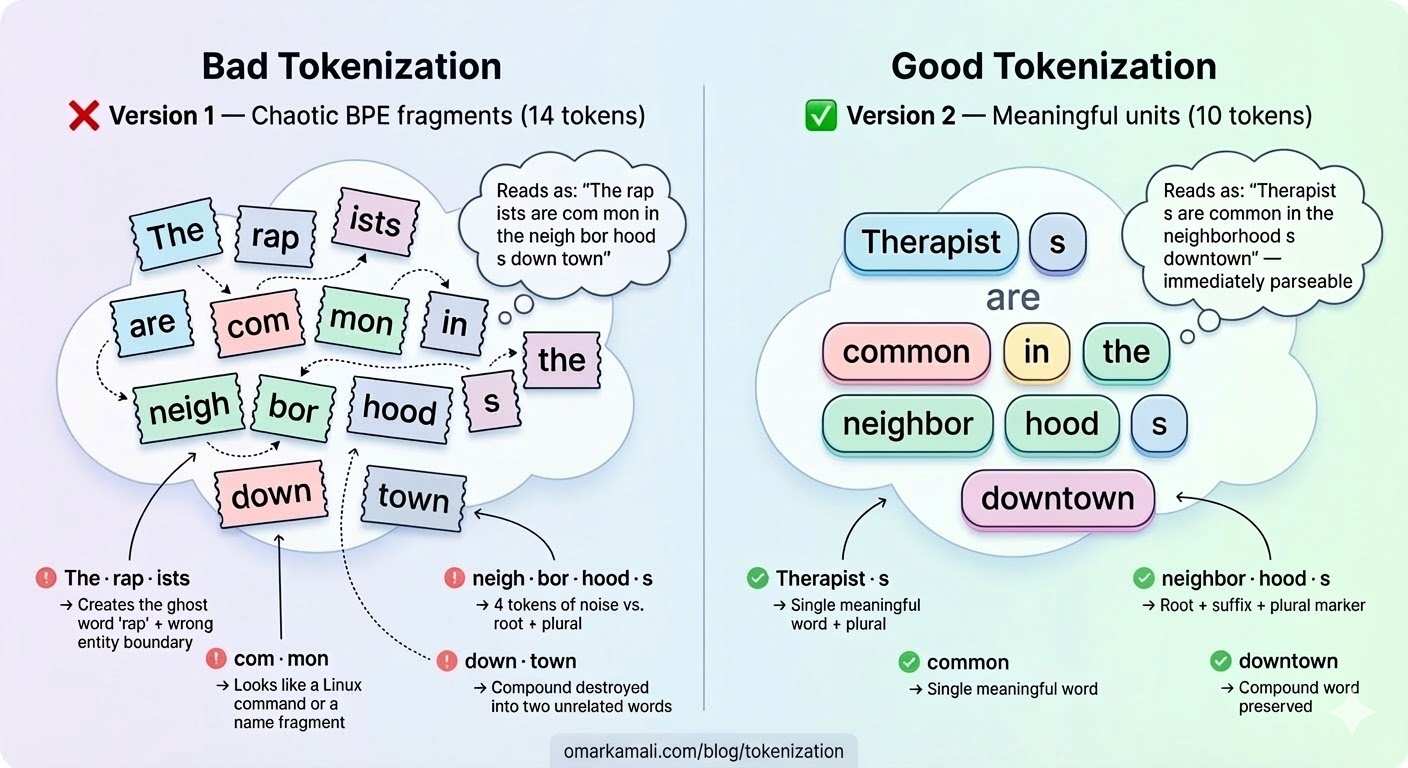
Tokenization can be constructive and produce useful segmentation such as below.
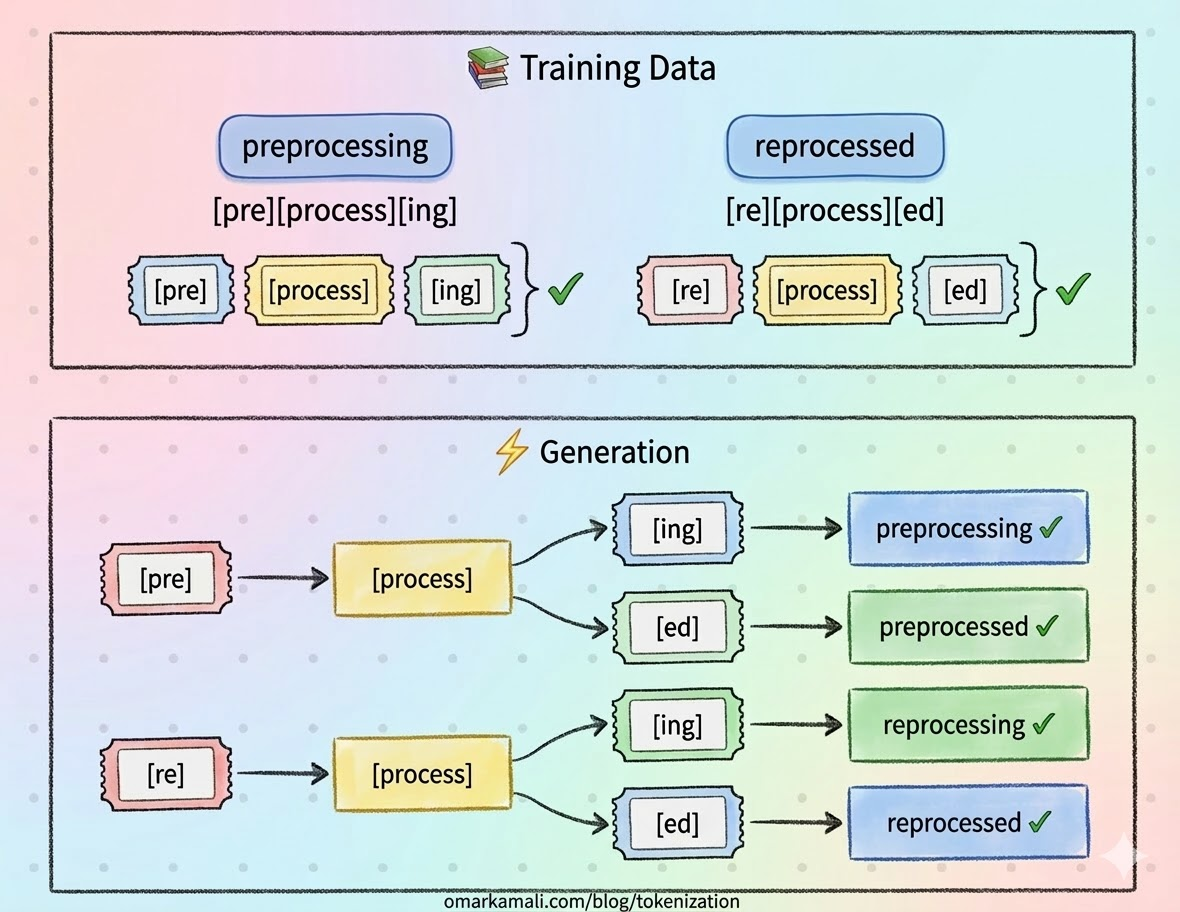
But it can also cause the opposite and generate non-existent words.
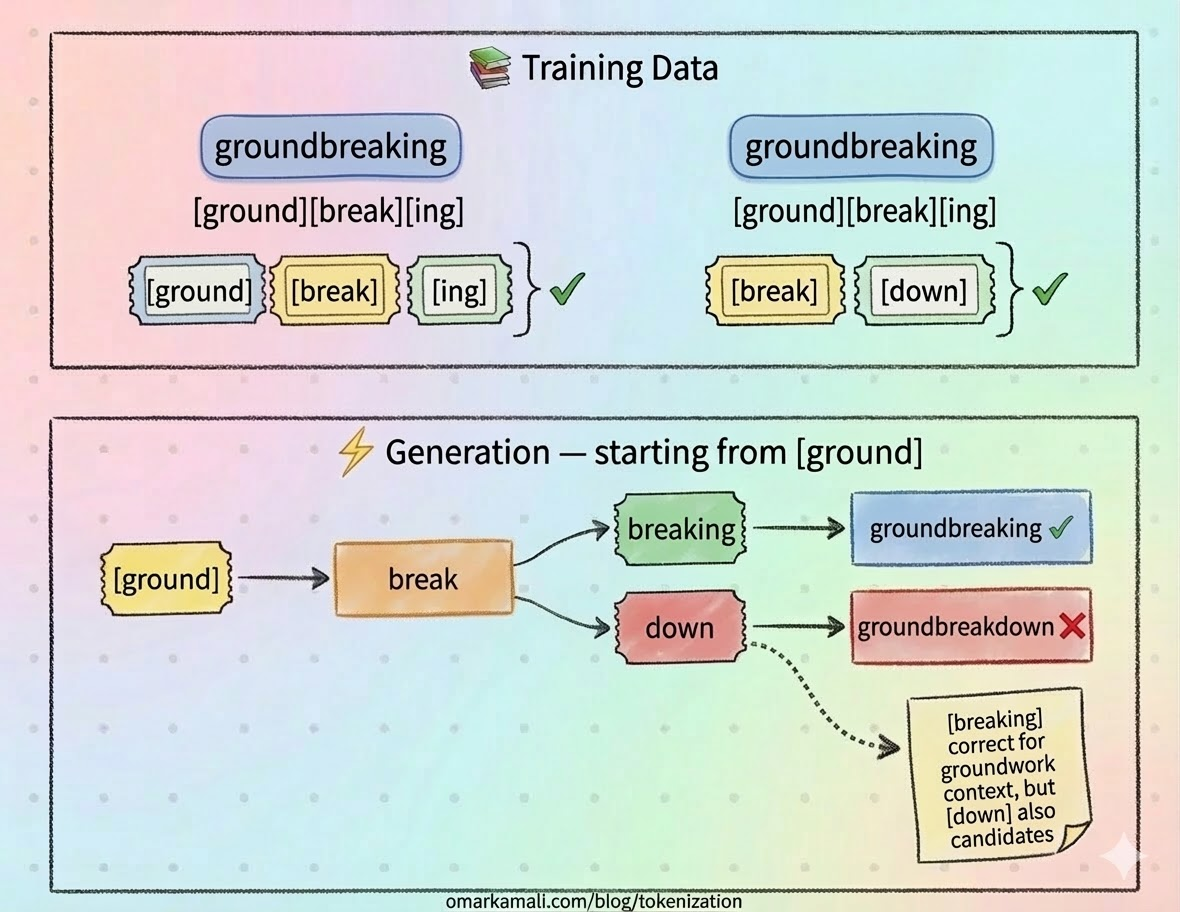
But tokens aren't just input and output units. They determine the legos the model uses to build meaning internally too. Every concept it holds, every relationship it reasons about, every pattern it recognizes is assembled from those same bricks. If your legos are weirdly shaped, if they don't map cleanly onto the things you're trying to build, what you construct will fit together awkwardly and break in unexpected places. The structure looks roughly right from a distance. The details are wrong.

What is this monstrosity?
The Obvious Fix That Doesn't Scale
At this point you might think, "just" make a tokenizer for your language and make it fit your language's quirks. And you should, it's much better than using an English vocabulary or something even less meaningful. Wikilangs makes such tokenizers available for 340+ Wikipedia languages precisely because the alternative is worse.
But a custom tokenizer is a local optimization, not a solution. It reduces fertility. It partially improves boundary coherence. It does nothing for the variant recovery problem, since your tokenizer was trained on whatever clean text you had, not on the full distribution of how real speakers actually write and all the typos and variations that come with it.
More fundamentally, it destroys cross-lingual alignment: the moment you train a language-specific vocabulary, you diverge from the shared embedding space that makes multilingual transfer possible. Every token you add is a token the model has never seen in relation to the rest of its knowledge so you have to train it from scratch to a level the model can integrate it in its internal process.
The field has tried vocabulary expansion, token merging, bilingual tokenizer training, and script-specific sub-tokenizers. Each helps one language in isolation. None of them compose well. The dream of a single model that natively handles Arabic, Darija, Amazigh, Yoruba, and Khasi remains structurally blocked at the tokenization layer.
Looking at the numbers, let's say you add 4000 tokens per language, and that's on the extremely low bound. Over 340 languages means more than 1 million tokens the LLM should be able to handle. Such a vocabulary size is impractical. It increases the size of the model immensely (your 4B model becomes 20B with no gain in performance or output quality) and makes the generation step extremely slow due to the specifics of how the softmax function works.
You simply cannot patch your way to true multilingualism one vocabulary at a time.
What the Metrics Measure
Compression ratio and fertility are the two numbers everyone reaches for when evaluating a tokenizer. They're easy to compute, easy to compare, and easy to misread.
Fertility is defined as the average number of tokens per word. If a word is split in two tokens, that's a fertility of two. In general you want this number to go down. For morphologically rich languages (using prefixes and suffixes or more complex structures), a higher fertility might be desirable as long as the tokens map to inflection points in the language, rather than letter chunks with no particular meaning on their own. In general, a higher fertility means the model is doing more work per word, is slower, and has a higher chance of making mistakes.
Compression ratio on the other hand counts the ratio of bytes of text per token. Since tokens operate effectively as a lookup table, tokens that map to longer text result in better compression.
Like fertility, a better compression ratio means the model spends less effort for the same amount of text, ending up with higher output speed compared to a lower compression ratio.
Like many statistical figures, two very different tokenizers can result in the same fertility and compression ratios. Fertility simply tells you how long the sequence is. It says nothing about whether the cuts are meaningful. Compression ratio on the other hand is about pattern matching, and is also completely unconstrained by language morphology causing the results to diverge in ways that are destructive to the LLM.
| Tokenizer | Tokens |
|---|---|
| ❌ Bad | ev · lerd · en |
| ✅ Good (language-aware) | ev · ler · den |
In Turkish: "evlerden" (= "from the houses") = ev (house) + ler (plural) + den (ablative). The bad tokenizer destroys both plural and case information resulting in worse language modeling.
A 2025 ICML study across 70 languages confirmed the gap: morphological alignment does not explain much variance in model performance when measured by fertility alone, and oversegmentation can actually inflate apparent alignment scores. Other supporting metrics such as STRR (how many words are single tokens) do nothing to help here.
Better proxies exist, and MorphBPE's Morphological Consistency F1 and Morphological Edit Distance are both predictive of training convergence speed in ways fertility simply isn't. But the noisiness of data (typos and the like) in the wild means that a pure morphological approach is not always possible.
Next: Part 2 — The Hidden Tax Your LLM Pays for Bad Tokenization, where we dig into what happens inside the model when tokenization goes wrong.
Related posts
Interested in collaboration?
I'm open to research partnerships, compute collaborations, or contributing to low-resource language AI.
Get in touch